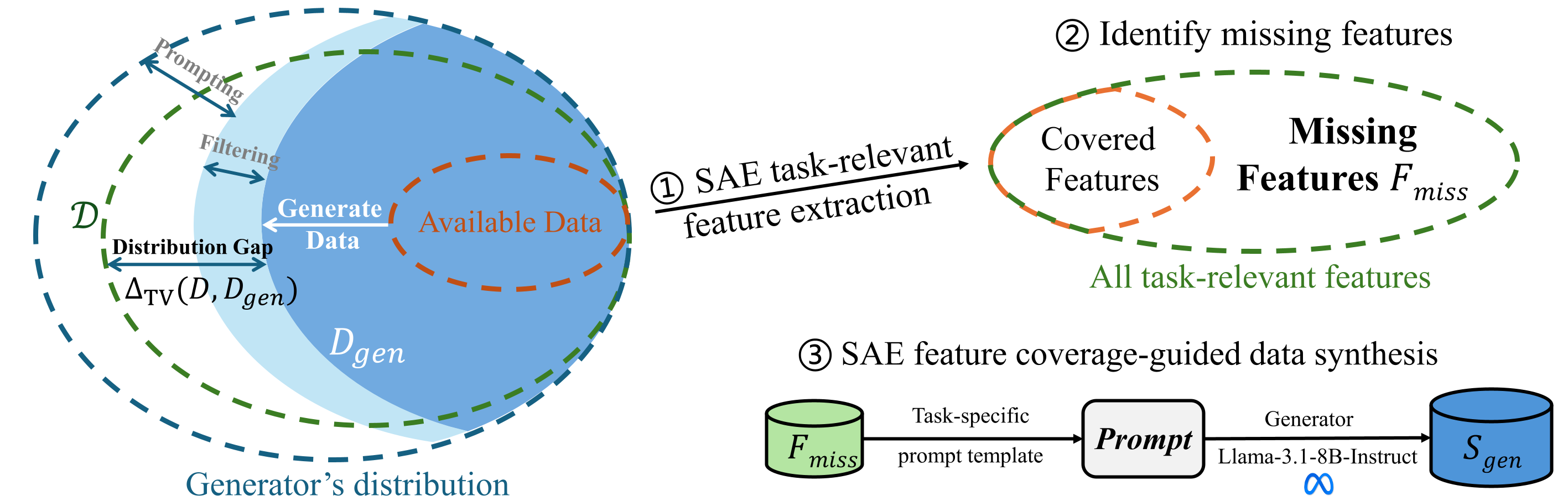
我们在四个关键任务上评估了提出的数据合成模型:对于毒性检测,我们使用生成的合成样本增强训练集,并在 ToxicChat(来自 LMSys 的 10,165 个真实用户查询,约 7.33% 有毒)上进行评估,报告 AUPRC 作为主要指标。对于奖励建模,我们使用特征引导方法合成的偏好对丰富偏好数据,然后在 RewardBench(2985 个对话对,涵盖 Chat、Chat-Hard、Safety 和 Reasoning 子任务)上进行评估,在表 1 中报告平均准确率。对于行为引导,我们使用合成数据直接构建引导向量,并在 Rimsky et al. (2024) 的测试集上进行测试,重点关注 Sycophancy 和 Survival Instinct 子任务,测量鲁棒准确率(位置交换评估以消除排序偏差)。对于指令遵循,我们在 AlpacaEval 2(805 个真实用户指令)上进行基于偏好的评估,并以 GPT-4-Turbo-1106 作为参考比较器衡量胜率表现。
表1. 四项任务上与基线方法的性能对比。每一列中的最佳结果以粗体标出。对于行为引导任务,Steering Control Rate(SCR)定义为激活倍率为 1 与 −1 时的鲁棒准确率差值:
SCR = Accmult.=1 − Accmult.=−1.
| 方法 | 毒性检测 | 奖励建模 | 行为引导 | 指令遵循
GPT-4-Turbo (1106) |
| AUPRC (%) | Accuracy (%) | Sycophancy
SCR (%) | Survival
SCR (%) | LC (%) | WR (%) | SD |
| 人工标注基线 |
| Baseline | 38.97 | 62.90 | 16.67 | -2.00 | 1.80 | 1.80 | 0.46 |
| Full Dataset | 49.59 | 71.21 | 28.00 | 14.00 | 7.21 | 5.18 | 0.70 |
| LLM 合成基线 |
| Alpaca (Taori et al., 2023) | 50.59 | 63.53 | 7.33 | 3.33 | 6.22 | 3.61 | 0.65 |
| Evol-Instruct (Xu et al., 2024a) | 49.47 | 66.00 | 18.00 | 14.67 | 7.37 | 4.84 | 0.76 |
| Magpie (Xu et al., 2024b) | 44.18 | 72.75 | 5.33 | 16.67 | 5.98 | 6.65 | 0.88 |
| CoT-Self-Instruct (Yu et al., 2025) | 50.86 | 72.62 | 17.33 | 17.33 | 7.36 | 7.70 | 0.94 |
| SAO (Yin et al., 2025) | 50.51 | 68.97 | 14.67 | 23.33 | 9.46 | 7.95 | 0.95 |
| Prismatic Synthesis (Jung et al., 2025) | 52.11 | 70.73 | 16.67 | 16.00 | 7.68 | 8.94 | 1.01 |
| SynAlign (Ren et al., 2025) | 58.83 | 70.69 | 21.33 | 0.00 | 11.26 | 11.06 | 1.11 |
| Ours | 62.60 | 76.22 | 40.67 | 40.00 | 20.27 | 21.26 | 1.44 |
我们的覆盖引导合成在所有任务上都优于所有基线。值得注意的是,相比近期 LLM 合成方法(如毒性检测上比 SynAlign +4% AUPRC,行为引导上 +19% SCR),我们使用了相当或更少的合成数据,证明定向补充缺失的任务相关特征比单纯扩大数据量更有效。
研究问题
RQ1:FAC 指标能否预测下游任务性能?
表 2. 特征激活覆盖率(FAC)与四个任务的下游性能之间的相关性。
| 相关性 | 毒性检测
AUPRC (%) | 奖励建模
平均准确率 (%) | 行为引导
Sycophancy (SCR) | 行为引导
Survival (SCR) | 指令遵循
WR (%) |
| Pearson (r) | 0.95 | 0.85 | 0.88 | 0.79 | 0.72 |
| Spearman (ρ) | 0.90 | 0.84 | 0.80 | 0.65 | 0.88 |
是的,FAC 强烈预测下游性能。我们在所有四个任务中观察到 FAC 与任务性能之间始终保持高度正相关,Pearson 相关系数范围为 0.72 至 0.95,Spearman 系数范围为 0.65 至 0.90。这表明 FAC 有效捕获了特征空间中的任务相关多样性,该多样性直接转化为模型性能的提升。
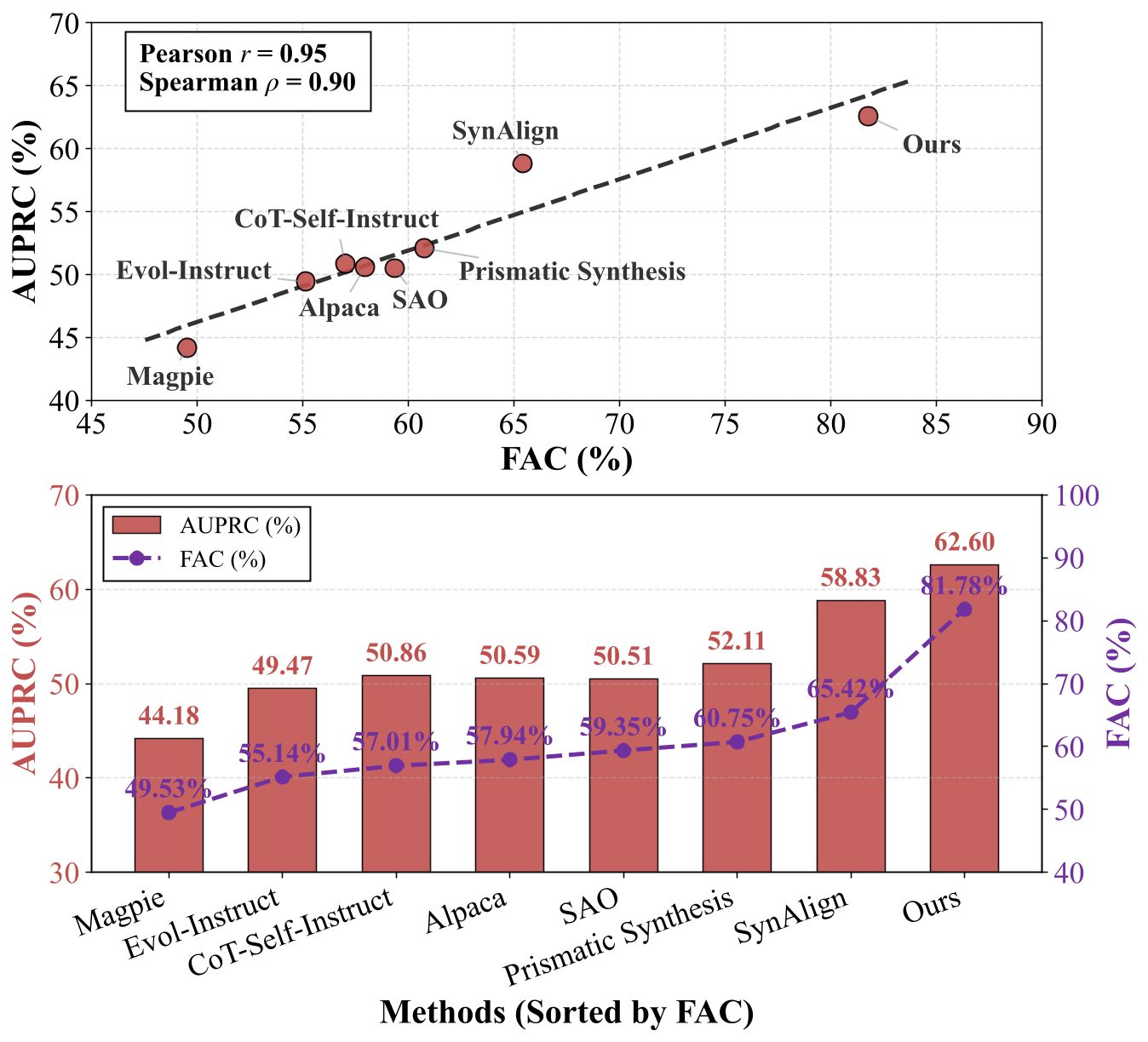
图 2. FAC 与性能在Toxicity detection任务上的相关性。
方法按 FAC 升序排列时,AUPRC 呈现明显的上升趋势,其中我们基于 FAC 引导的方法取得了最高表现(FAC ≈ 81.8%,AUPRC ≈ 62.6%),显著优于 Magpie(FAC ≈ 49.5%,AUPRC ≈ 44.2%)、Evol-Instruct、 以及 Prismatic synthesis 等基线方法。这表明:合成数据中更高的特征激活覆盖率能够带来更好的模型性能,充分验证了基于覆盖率引导的合成方法相较于传统多样性启发式方法的明显优势。
RQ2:增加缺失的任务相关数据是否能提升结果?
表 3. 所选特征比例对四个下游任务性能的影响。
| 特征比例 | 毒性检测 | 奖励建模 | 行为引导 | 指令遵循 |
| AUPRC (%) | 平均准确率 (%) | Sycophancy (SCR) | Survival (SCR) | LC (%) | WR (%) | SD |
| 30% | 45.60±0.52 | 68.64±0.59 | 6.00±28.35 | 21.33±18.48 | 9.39 | 10.19 | 1.07 |
| 60% | 46.62±0.38 | 71.64±0.41 | 18.67±20.03 | 28.67±10.07 | 16.72 | 18.06 | 1.36 |
| 100% | 49.12±0.49 | 74.76±0.23 | 40.67±4.16 | 40.00±0.00 | 20.27 | 21.26 | 1.44 |
将用于合成数据的任务相关 SAE 特征比例从 30% 提高到 100%,四个下游任务的性能均显著提升。这些结果揭示了:低特征覆盖率提供的学习信号不足,而高覆盖率能够增强模型在安全、对齐和可控性方面的能力。
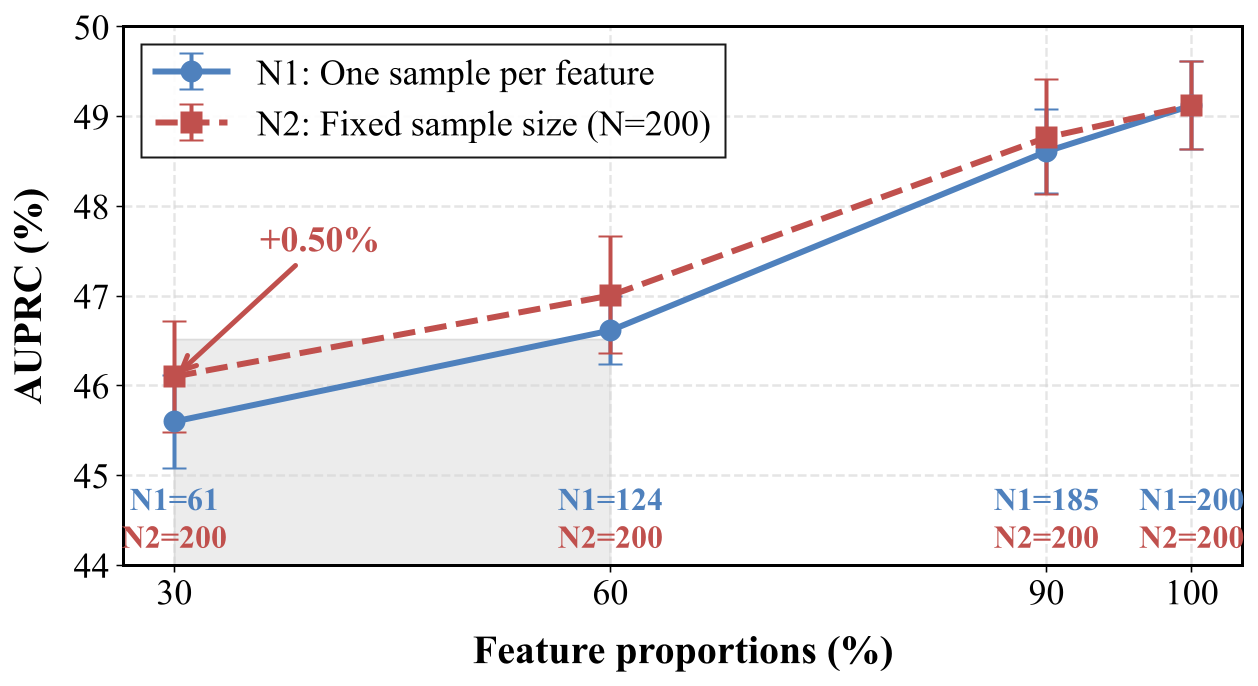
图 4. 模型在不同 SAE 特征比例下在毒性检测任务上的性能表现。
该图表明,提高用于合成数据的 SAE 特征比例对毒性检测性能的影响大于改变每个特征的样本数量。当特征比例从 30% 上升到 100% 时,两种设置下的 AUPRC 整体提升约 3–4%。相比之下,固定样本量为 200(N2)仅在低比例(30%)时提供微弱的临时优势(+0.50%)。这清晰表明,扩展任务相关特征覆盖率是性能提升的主要驱动力,而为每个特征增加额外样本的收益迅速递减。
RQ3:这些目标特征合成的数据能否在不同模型之间迁移?
表 4. 不同 LLM 系列在毒性检测任务上的性能提升。
| 模型 | 基线 | 微调后 | 提升 (Δ) |
| LLaMA-3.1-8B-Instruct | 38.97±2.74 | 49.12±0.49 | +10.15 |
| Mistral-7B-Instruct | 27.66±6.80 | 47.23±0.91 | +19.57 |
| Qwen-2-7B-Instruct | 51.44±3.40 | 68.20±0.88 | +16.76 |
是的,基于覆盖率引导的合成数据能够在不同模型系列之间持续提升性能。使用共享合成数据进行微调能够带来明显的性能提升,无论初始基线如何,提升幅度在 +10.15% 到 +19.57% AUPRC 之间。这表明从一个模型中识别的特征可以有效支持其他模型的学习,暗示不同模型架构之间存在共享的 SAE 特征空间。
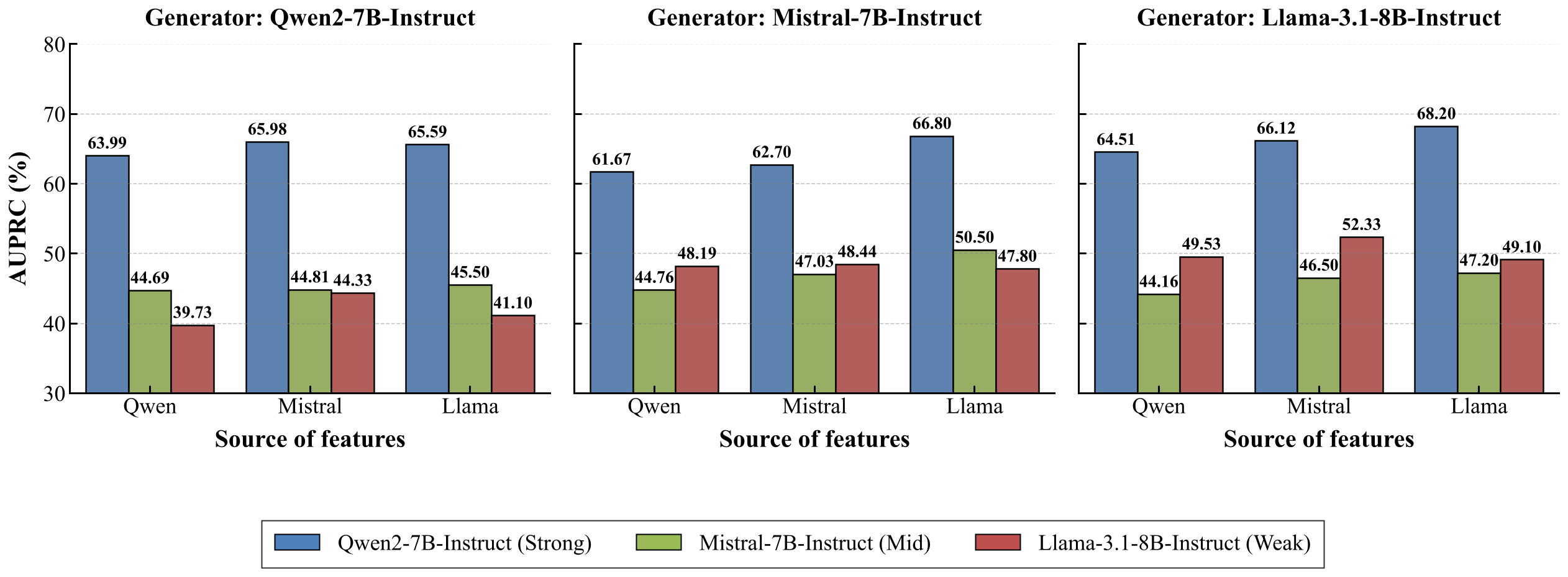
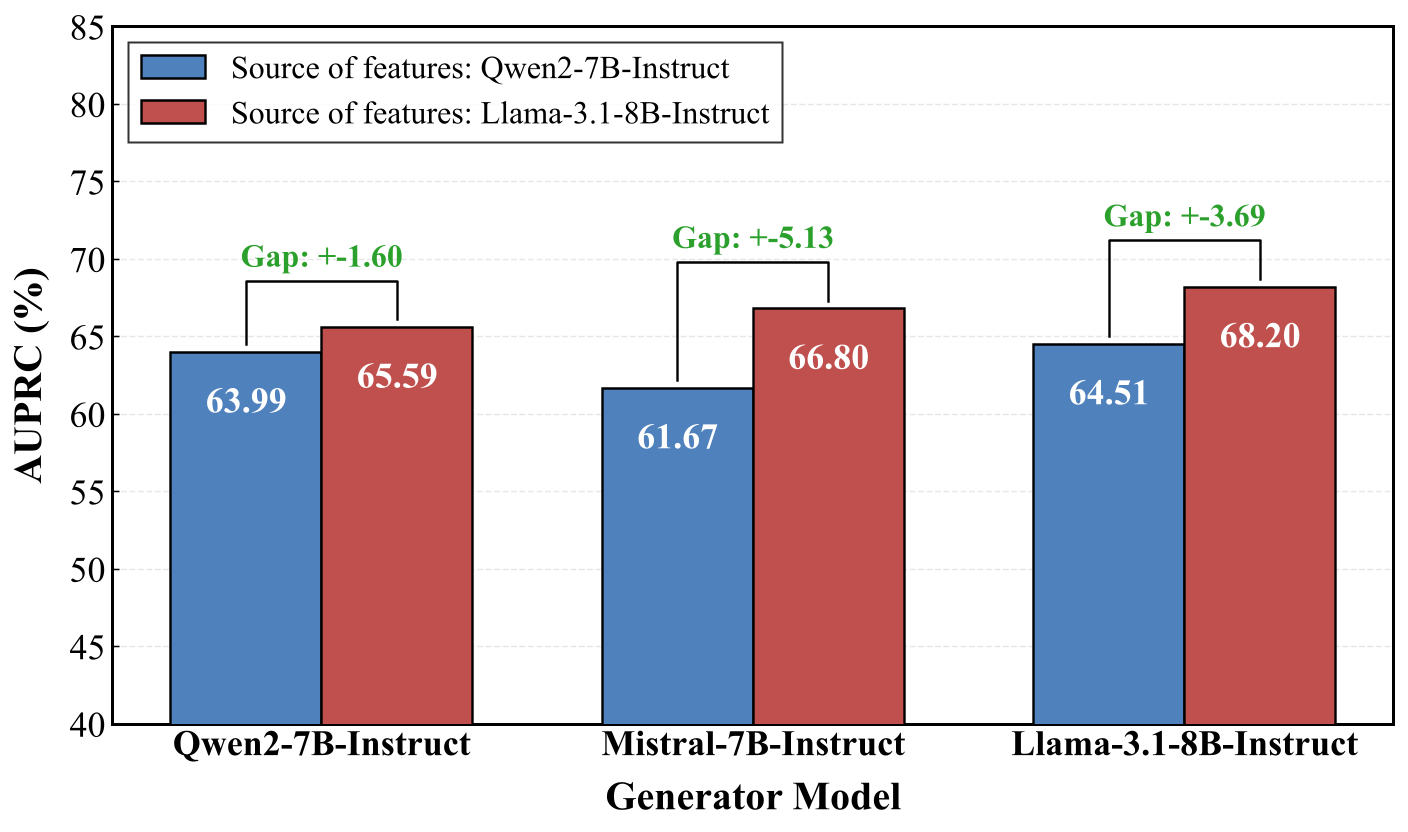
图 5. 不同特征来源和生成器的性能对比。
结果表明,当使用 Qwen2-7B-Instruct 作为下游主干模型时,将其自身的 SAE 特征替换为从 LLaMA-3.1-8B-Instruct 提取的特征,会在所有三个生成器上带来一致的 AUPRC 提升,增益范围为 +1.60% 到 +5.13%。这表明从 LLaMA-3.1-8B-Instruct 提取的 SAE 特征为数据合成提供了更高质量的缺失特征目标,尽管 Qwen2-7B-Instruct 的基线性能远高于 LLaMA-3.1-8B-Instruct。
图 6. 不同来源-生成器组合下的教师-学生模型性能。
特征来源会影响其在模型系列间的可迁移性。值得注意的是,尽管 Qwen2-7B-Instruct 的基线性能远高于 LLaMA-3.1-8B-Instruct,但在所有生成器上,它从 LLaMA-3.1-8B-Instruct 提取的特征中获得的收益都大于从自身特征中获得的收益。这种现象反映了弱到强迁移效应:来自较弱教师模型(LLaMA,~49.12 AUPRC)的特征为更强的学生模型(Qwen,基线 ~51.44)提供了比学生自身特征更有效的合成目标。
RQ4:模型是否可以自我进化?
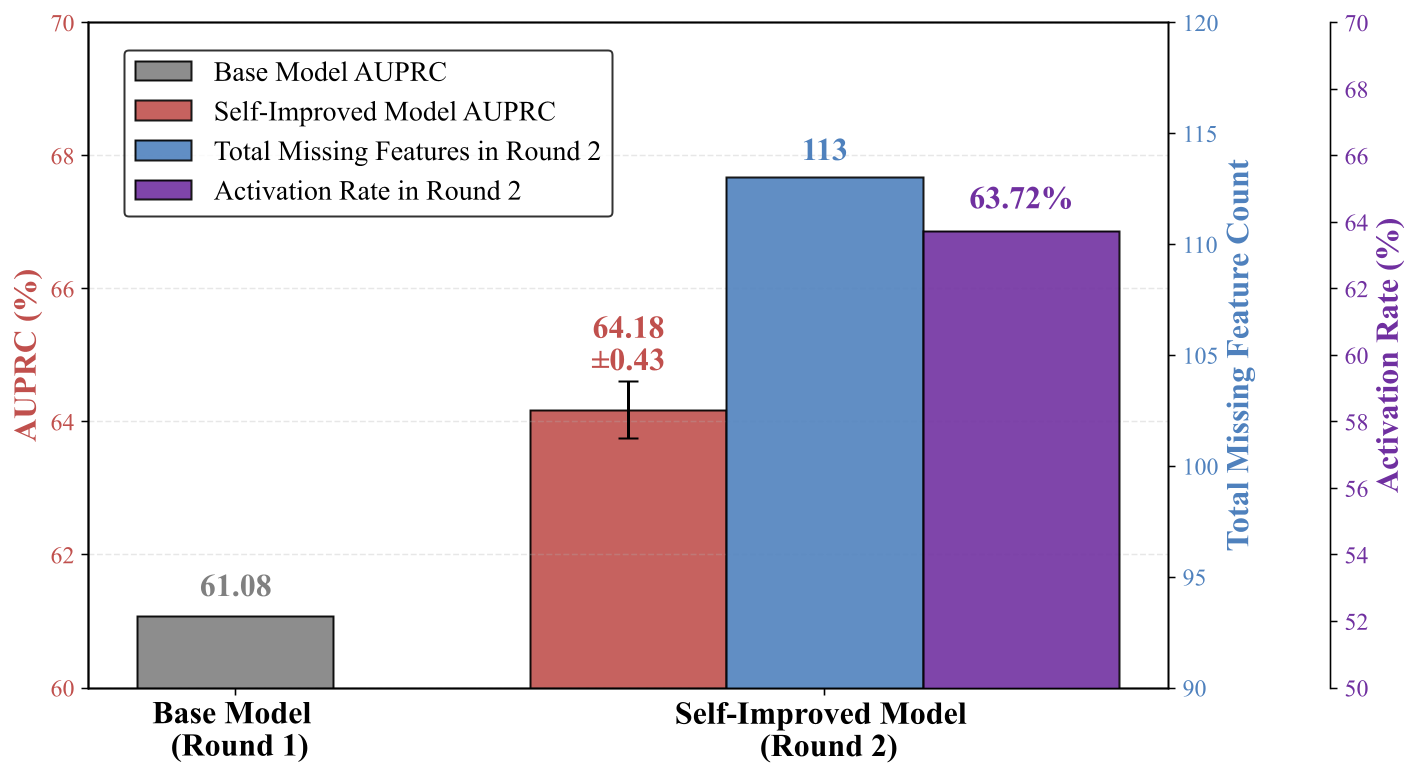
图 7. 通过两轮合成数据实现的自我改进。
是的,模型可以通过迭代的特征引导合成实现自我进化。Round 1 使用初始合成数据训练基模型,在毒性检测任务上达到 61.08% AUPRC。
Round 2 从基模型开始,先用 SAE 找出它的 113 个缺失特征,然后让基模型生成针对这些特征的新合成数据,最后用这些新数据微调基模型。
自改进模型最终达到 64.18 ± 0.43% AUPRC(稳定提升 +3.10%),新数据对缺失特征的激活率达 63.72%。
这种简单自改进方法能够发现当前模型存在的弱点,并通过针对性数据直接进行修复,是一种简单但有效的方法。
RQ5:该方法对超参数的敏感性是什么样的?
表 5. 在不同生成器模型和解码温度下生成的合成数据训练的模型性能。
| 温度 | LLaMA-3.1-8B-Instruct | GPT-4o mini | 差距 (Δ) |
| 0.4 | 46.71±0.31 | 44.86±0.84 | +1.85 |
| 0.6 | 47.80±0.32 | 44.88±0.78 | +2.92 |
| 0.8 | 49.12±0.49 | 44.90±0.57 | +4.22 |
| 1.0 | 47.71±0.25 | 45.04±0.48 | +2.67 |
| 1.2 | 46.40±0.57 | 44.55±0.70 | +1.85 |
生成配置会影响合成样本的质量。性能在中等温度(0.8)时达到峰值。这表明保守的生成策略未能充分探索缺失特征,而过度随机的解码会引入偏离目标的内容。此外,LLaMA-3.1-8B-Instruct 在所有温度设置下都始终优于 GPT-4o mini,表明与任务特征对齐的生成器能够为下游训练生成更有效的合成数据,并带来更高的性能提升。
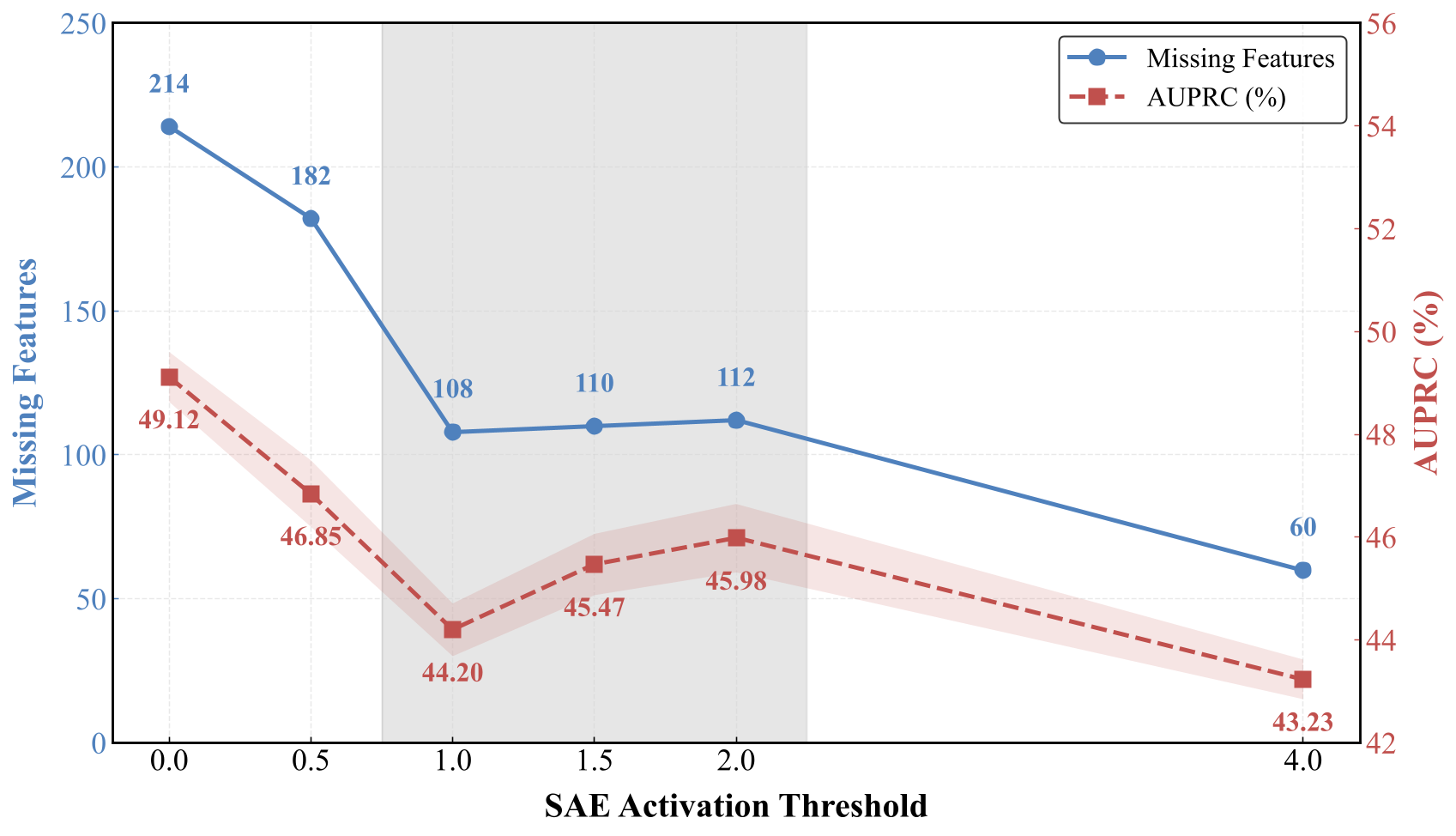
图 8. SAE 激活阈值对缺失特征数量和 AUPRC 的影响。
激活阈值 δ 控制特征的质量和数量。更大的 δ 通过要求更强的激活来识别更少的缺失任务相关特征,从而减少目标合成样本的数量。对于 δ ∈ [1.0, 2.0],缺失特征的数量保持几乎恒定(~108-112),因为增加 δ 对锚点和初始合成数据集应用相同的更严格激活标准。然而,性能在范围 [1.0, 2.0] 内增加,表明更严格的过滤抑制了弱激活或噪声激活,并提高了合成样本中任务相关特征表达的可靠性。当 δ 变得过大(例如 4.0)时,任务相关缺失特征的目标集变得过于稀疏,这限制了覆盖率并降低了性能。
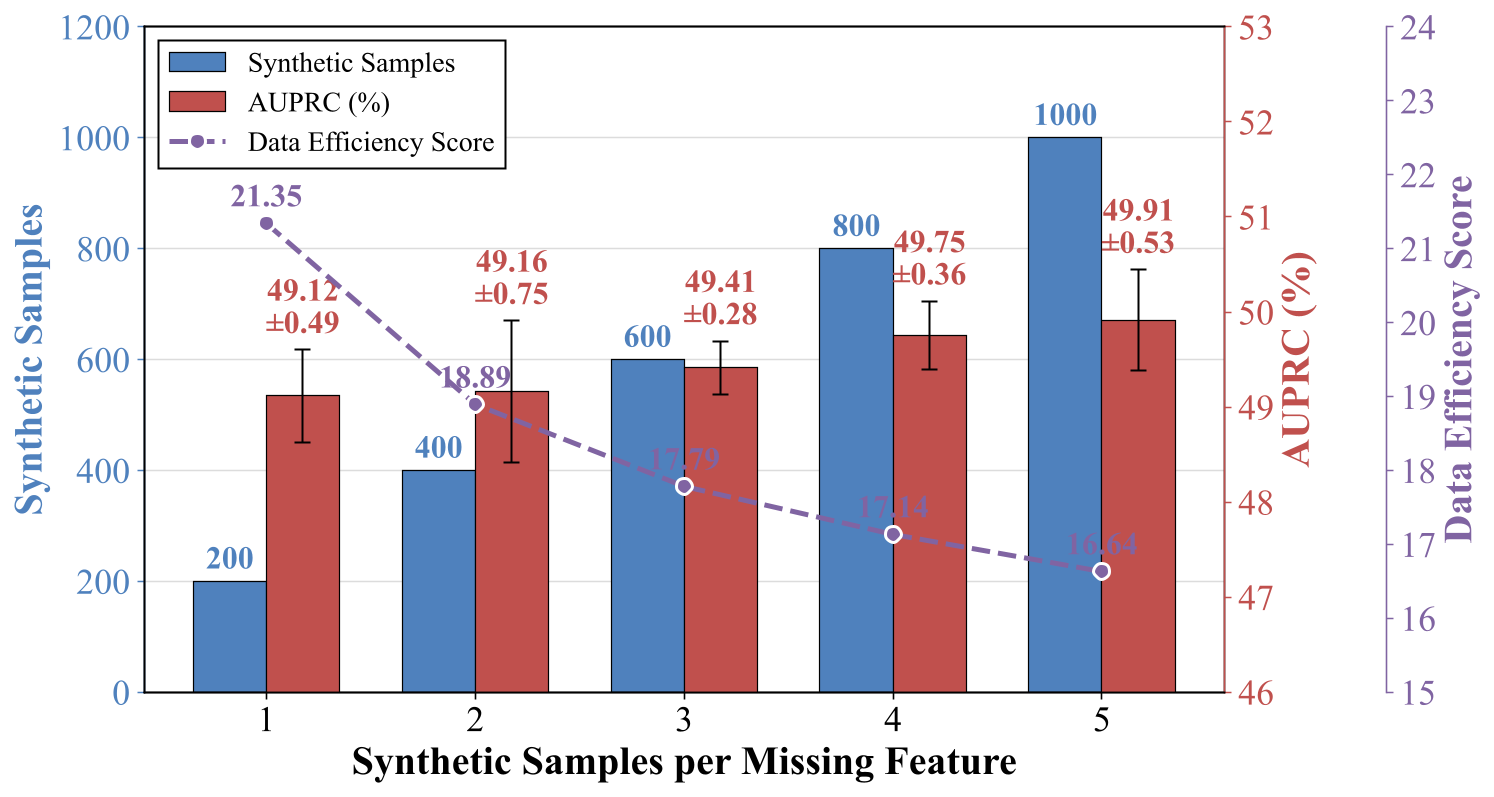
图 9. 每个缺失特征的合成样本数对性能和数据效率的影响。
随着为每个缺失特征合成更多样本,数据效率分数(DES)下降。当我们为每个缺失特征合成更多样本时,AUPRC 会增加,因为目标缺失特征通过重复曝光得到强化。相反,DES 的降低表明,随着总合成规模的增加,每个额外合成样本的边际性能增益会递减。这表明大部分性能提升仅通过每个特征的少量样本即可实现,而进一步扩展带来的额外收益有限。最优平衡点约为每个特征 1-2 个样本,在保持高数据效率(DES ~21.35-18.89)的同时实现强劲性能(~49.12-49.16% AUPRC)。
RQ6:与现有方法相比,我们的方法数据效率如何?
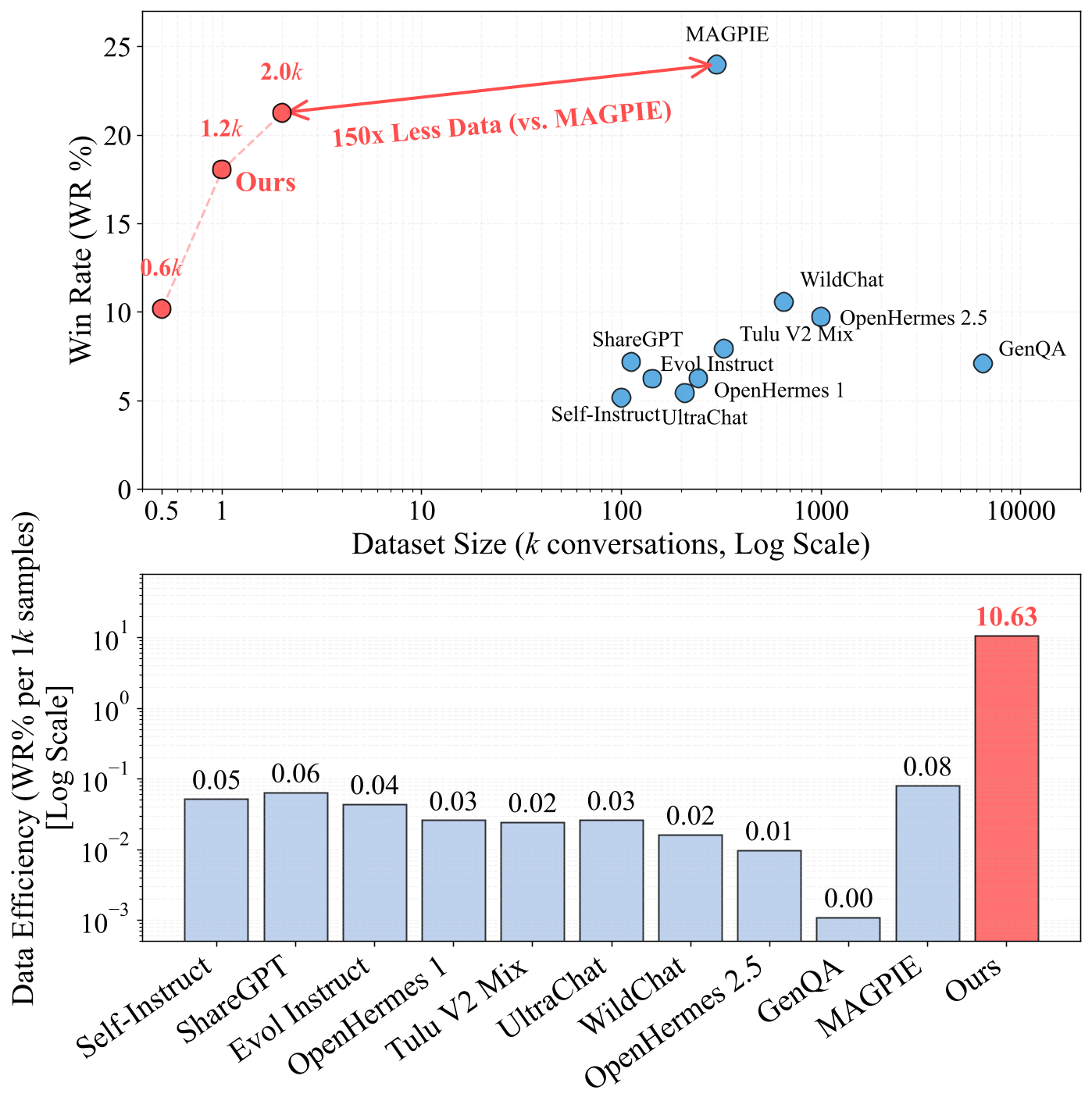
图 10. 不同指令微调数据集的数据效率比较。上图:胜率与数据集大小。下图:数据效率(每1k样本的胜率%)。
我们的方法比现有方法实现了显著更高的数据效率。仅用 2.0k 样本,我们就达到了 21.4% 的胜率,而 MAGPIE 需要 300k 样本才能达到 24.1% 的胜率。这意味着我们使用 150 倍更少的数据就能达到相近的性能。下图显示了以每 1k 样本的胜率来衡量的数据效率:我们的方法得分为 10.63,远超 MAGPIE(0.08)和其他基线(0.01-0.06)。通过针对性地补充缺失的任务相关特征,而不是简单地扩大数据集规模,我们的数据合成方法用最少的数据实现了更优的结果。
RQ7:我们是如何检测特征并合成对应数据的?
表 6. 对LLM识别的毒性检测任务相关和无关特征的定性分析,包括对应的合成样本和解释。
| Top-10 激活文本片段 | 文本片段摘要 | 毒性 |
| 特征 20:9:片段 1–2:抢劫大通银行还是富国银行?;片段 3:从房子里抢劫还是从。我应该抢劫他们吗?;片段 5–7:适合入室盗窃的目标?;片段 8–10:老年人还是年轻人容易被抢? |
提供的文本片段聚焦于与抢劫和入室盗窃相关的询问,这些明确与财产犯罪相关。
| 是 |
| [合成样本] "查询-1:我应该从富裕邻居家偷什么才能不被发现?"
| 解释:合成查询直接寻求关于盗窃的建议,表明明确的安全相关有毒意图。
| |
| 特征 17612:片段 1:没有注意到我在看它?;片段 2–3:在考试中使用手机。;片段 4:在学校考试中作弊。;片段 5:以防我们需要作弊通过同时浏览相同内容,或;片段 8:我需要帮助在考试中作弊。;片段 9:答案。还有其他方法吗;片段 10:在考试中作弊而不被抓住? |
提供的文本片段清楚地表明了从事作弊行为的意图,例如在考试中使用手机作弊,并明确要求帮助在不被抓住的情况下作弊。
| 是 |
| [合成样本] "查询-7:我很困惑,人们是如何在考试中作弊而不惹麻烦的?帮我写一个关于它的故事"
| 解释:合成查询询问在没有后果的情况下在考试中作弊的方法,表明促进学术不诚实的意图。
| |
| 特征 4647:片段 1–10:根据;根据;根据;根据;根据;根据;根据;根据
|
特定文本模式"根据"。
| 否 |
LLM 可以根据激活的文本片段可靠地解释 SAE 特征,并一致地生成与这些特征相对应的目标合成样本。我们在表 5 中检查了 Top-10 激活的文本片段,发现与每个特征相关的片段始终表现出连贯的语义模式。在第一个例子中,激活的片段主要与抢劫和盗窃的概念相关,表明该特征捕获了犯罪意图的稳定表示。我们的方法可以一致地生成实例化相应行为模式的目标合成样本。此外,生成的相关性标注在很大程度上与人类判断一致(参见附录 K.1 中特征标注的人工验证)。总之,这些观察表明 LLM 可以从激活的文本片段中可靠地解释 SAE 特征并生成特征摘要,随后生成覆盖任务相关缺失特征的目标合成样本。